XPath
XPath in simple terms is a way of finding an element(s) in an HTML DOM by giving its path. It is useful when name or id etc is not available to be directly used to find the element. The path given can be either Absolute or Relative.
-
Absolute:
An absolute path is a way in which the complete path of the element is given.
Example - html/body/div[1]/section/div[1]/div/div/div/div[1]/div/div/div/div/div[3]/div[1]/div/h4[1]/b
The disadvantage of using this is that even if there is a little change in the path, maybe a div is removed or added, this XPath is unusable, it will simply throw an error. It is useful in certain situations which are mentioned below as you read.
-
Relative:
Relative path as the name suggests uses double slashes to move through the path. It may consist of wildcard(*), attribute name with its value. They can be used in combination such as in the example below where we are using the class name.
Example - //*[@class='featured-box']
As we can see it is much shorter and versatile, therefore, it reduces the chance of a mistake.
Environment for Building an XPath
In order to build an XPath, open a browser such as Chrome and go to developer tools. Inspect an element and copy the XPath provided by the browser by default.
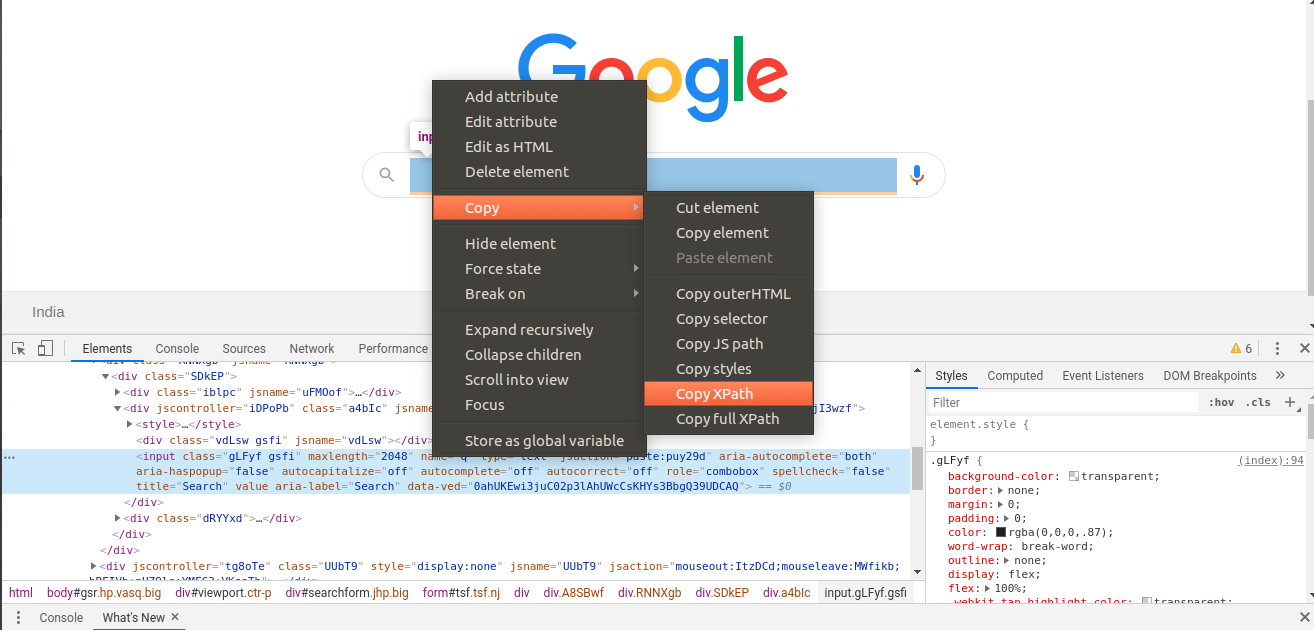
It is a good starting point but we should always make our own custom XPath because it may not always work and it can be shortened this way. Example – sometimes we want to find an element where only one attribute is given say a class name but there are other elements with that class name. On Gmail, if you type “//div[@class = ‘Xb9hP’]”
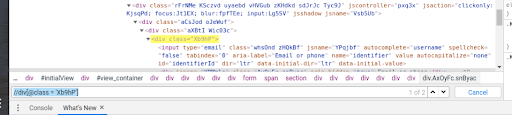
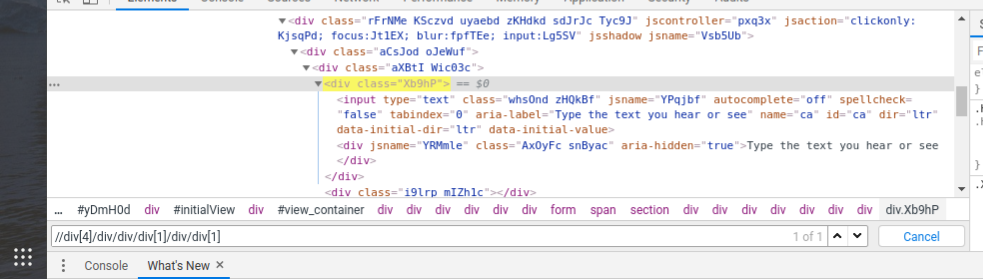
It will find multiple elements. It will always point to the 1st occurrence by default, in order to find XPath for the second one. We need to use absolute Xpath. By default it will be :
/html/body/div[1]/div[1]/div[2]/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[4]/div/div/div[1]/div/div[1]
Now, this is very lengthy. We can shorten that by making our custom XPath. It uses Double slashes which means to find all Descendents from the last step in the DOM(Single slash means find only the first child of the current element):
//div[4]/div/div/div[1]/div/div[1] . You can explore this.
Note – Make sure when you write an Xpath, there should always be “one matching result”. If there are more, your XPath will not work unless you are looking for multiple elements.
-
Basic XPath:
This Xpath consists of a simple attribute such as a id, name, class name etc.
//*[@name = “q”] or //input[@name = “q”]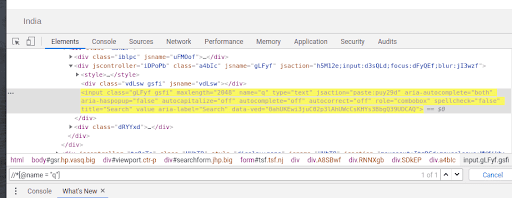
-
Contains():
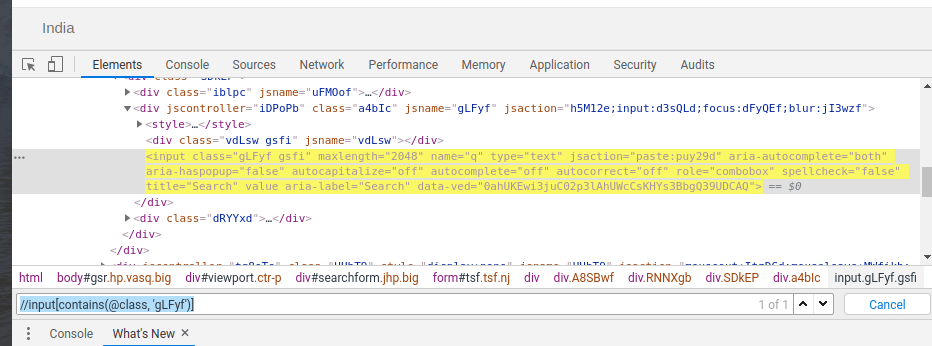
It is a method in Xpath that allows partial text to find an element. It is useful when the value of an attribute gets changed dynamically. So, we don’t need to write the exact text. Eg – //input[contains(@class, ‘gLFyf’)]. Here the complete name of the class is “gLFyf gsfi”. We could have used any attribute such as ‘type’.
-
OR & AND:
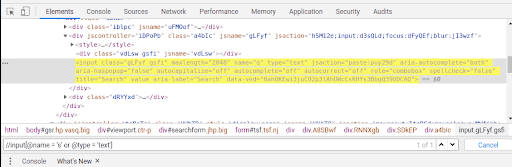
OR – Anyone condition could be true for finding the element. Both can be true as well. Eg – //input[@name = ‘s’ or @type = ‘text’]. Here the value of name is wrong but the type is correct having only one instance.
AND – Both the conditions need to be true for this to work. It is useful in case if none of the attributes can individually find the element.
Eg :-//input[@aria-label = ‘Google Search’ and @data-ved = ‘0ahUKEwi3juC02p3lAhUWcCsKHYs3BbgQ4dUDCAY’]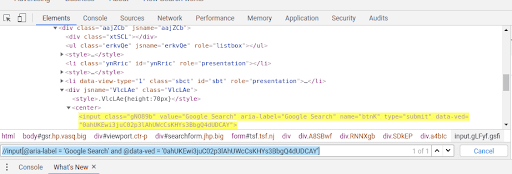
-
Text():
Text function allows us to build XPath using the text.
Eg – //div[text() = “Email or phone”]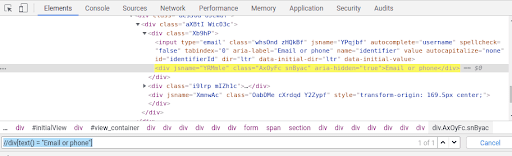
You can also use it in combination with the contains a method to use the partial text.
Eg – //div[contains(text(), “Email”)] -
Start-with Method:
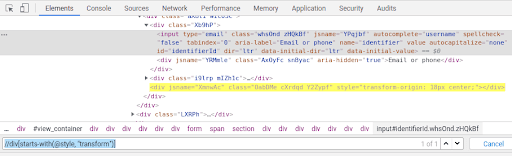
This function is useful when the value of the attribute changes dynamically but the starting of all these values are same. Eg – //div[starts-with(@style, “transform”)]
-
Axes Methods:
- Following:
This method finds all succeeding elements of the mentioned element based on the tag name.
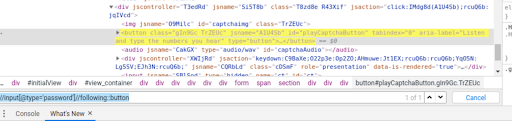
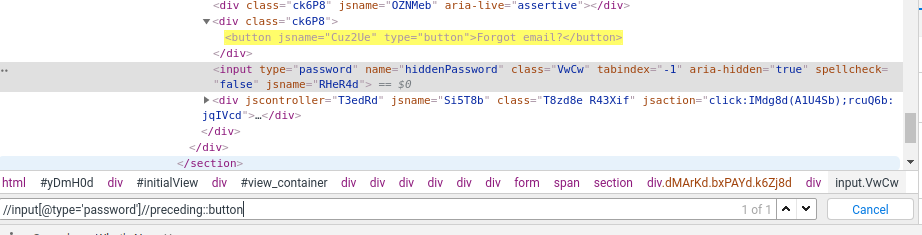
- Preceding: This method finds all the preceding elements of the current node.Eg – //input[@type=’password’]//preceding::button
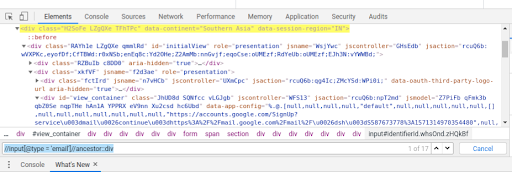
- Ancestor: This methods selects all ancestors element (grandparent, parent, etc.) of the current node. Eg – //input[@type = ‘email’]//ancestor::div
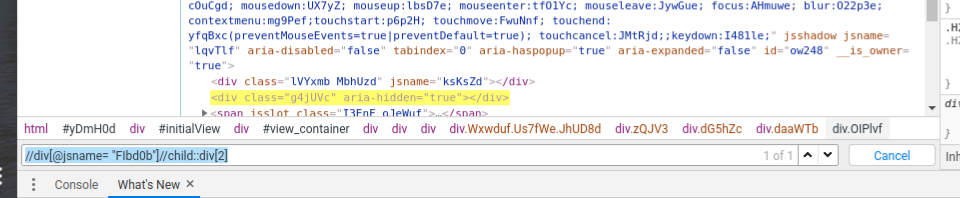
- Child: This method finds all the child elements of the mentioned elements. Eg – //div[@jsname= “FIbd0b”]//child::div[2]
- Parent:
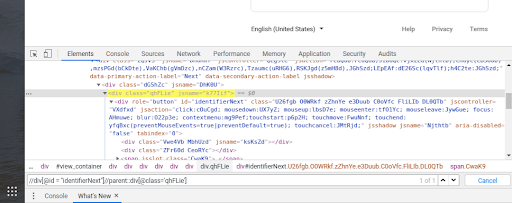
This method allows finding parent of the current node. Eg – //div[@id = “identifierNext”]//parent::div
It seems complicated at first but it is very simple.You can use an attribute to uniquely identify the parent.
- Descendant:
This method finds all the children, grandchildren etc. Eg – //div[@class = ‘Xb9hP’]//descendant::input[@type = ’email’]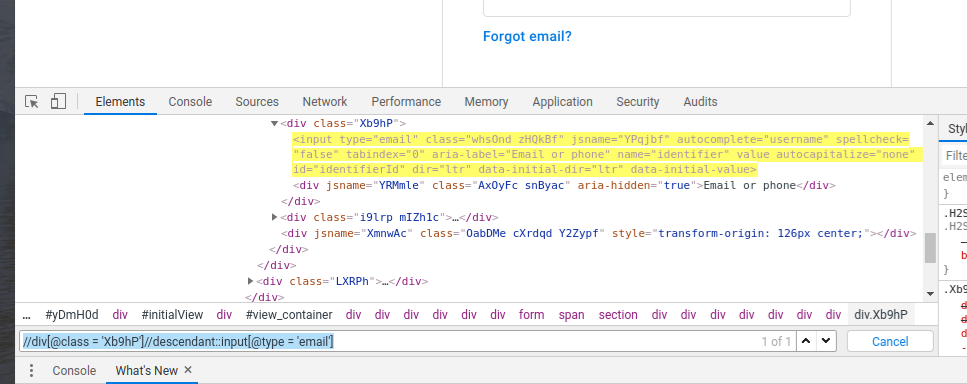
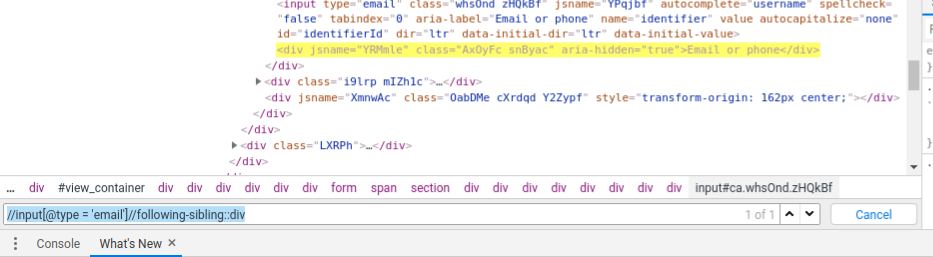
- Following-sibling:
This method finds out all the following siblings of the current element. Eg – //input[@type = ’email’]//following-sibling::div
- Following: